如果要判斷矩形是橫向或是縱向,通常可以直接看出結果。
可以將所有矩形左下角跟原點對齊,以右上角的座標位置,來判斷橫或縱向。分類就是要找出一條分類的線,將兩種矩形分類。


這條線,是將權重向量 (weight) 視為法線的直線,因為互相垂直,所以內積為 0。
\(w \cdot x = \sum_{i=1}^{n} w_ix_i = 0\)
如果有兩個維度,且 \(weight = (1,1)\)
\(w \cdot x = w_1x_1 + w_2x_2 = 1 \cdot x_1 + 1 \cdot x_2 = x_1 + x_2 = 0\)

內積也可以用另一個式子
\(w \cdot x = |w| \cdot |x| \cdot cos𝜃\)
因為內積為 0,表示 \(cos𝜃 =0\),也就是 \(𝜃=90^o \) 或 \(𝜃=270^o\)
一般來說是要用機器學習,找出權重向量,得到跟該向量垂直的直線,再透過該直線進行分類。
感知器
感知器是一個可以接受多個輸入,並對每一個值,乘上權重再加總,輸出得到的結果的模型。

- 準備機器學習的資料
| 矩形大小 | 形狀 | \(x_1\) | \(x_2\) | \(y\) |
|---|---|---|---|---|
| 80 x 150 | 縱向 | 80 | 150 | -1 |
| 60 x 110 | 縱向 | 60 | 110 | -1 |
| 160 x 50 | 橫向 | 160 | 50 | 1 |
| 125 x 30 | 橫向 | 125 | 30 | 1 |
識別函數 \(f_w(x)\) 就是給定向量 \(x\) 後,回傳 1 或 -1 的函數,用來判斷橫向或縱向。
\(f_w(x) = \left\{\begin{matrix} 1 \quad (w \cdot x \geq 0) \\ -1 \quad (w \cdot x < 0) \end{matrix}\right.\)
回到 \(w \cdot x = |w| \cdot |x| \cdot cos𝜃\) 這個式子,如果內積為負數,那麼表示 \( 90^o < 𝜃 < 270^o\)
內積是用來表示向量之間相似程度,如果是正數,就是相似,0 是直角,負數代表不相似。
- 權重更新式
\(w := \left\{\begin{matrix} w + y^{(i)}x^{(i)} \quad (f_w(x) \neq y^{(i)}) \\ w \quad \quad \quad \quad (f_w(x) = y^{(i)}) \end{matrix}\right.\)
i 是學習資料的索引,這個權重更新是針對所有學習資料重複處理,用來更新權重向量。上面的部分,意思是藉由識別函數進行分類失敗時,才要去更新權重向量。
權重向量是用隨機的值初始化的

因為一開始識別函數的結果為 -1,而學習資料 \(y^{(1)} =1\),所以要更新權重向量
\( w + y^{(1)}x^{(1)} = w + x^{(1)}\)

運用向量加法得到新的 w,而新的 w 的法線,會讓 (125, 30) 跟 w 向量在同一側。
線性可分離
感知器有個缺點,只能用來解決線性可分離的問題,以下這樣的問題,無法用一條線去分類。

所以如果要處理圖片分類,就沒辦法以線性的方式處理。
上面例子是單層的感知器,多層感知器,就是神經網路。
另外有一種方法,可用在線性不可分離的問題上:邏輯迴歸 Logistic Regression
邏輯迴歸 Logistic Regression
這種方法是將分類用機率來思考。以一開始矩形橫向或縱向的例子,這邊假設橫向為 1,縱向為 0。
S 型函數
前面的回歸有提到 \(f_𝜃(x) = 𝜃^T x\) 這個函數,可用最速下降法或隨機梯度下降法學習 𝜃,然後用 𝜃 求得未知資料 x 的輸出值。
這邊需要的函數為,其中 \(exp(-𝜃^Tx) = e^{-𝜃^T x}\) , e 為自然對數的底數 Euler's number (2.71828)
\(f_𝜃(x) = \frac{1}{1 + exp(-𝜃^Tx)}\)
會稱為 S 函數是因為如果將 \(𝜃^Tx\) 設為橫軸,\(f_𝜃(x)\) 設定為縱軸,會出現這樣的圖形

S函數的特徵是 當 \(𝜃^Tx = 0\) 會得到 \(f_𝜃(x) = 0.5\),且 \(0< f_𝜃(x) <1 \)
當作機率處理的原因是 \(0< f_𝜃(x) <1 \)
決策邊界
將未知資料 x 屬於橫向的機率設為 \(f_𝜃(x)\) ,用條件機率的方式描述為
\(P( y = 1 | x) = f_𝜃(x)\)
當給予資料 x 時,y=1的機率為 \(f_𝜃(x)\) 。如果計算後的結果,機率為 0.7,就表示矩形為橫向的機率為 0.7。以 0.5 為閥值,判斷是不是橫向。
\(y = \left\{\begin{matrix} 1 \quad (f_𝜃(x) \geq 0.5) \\ 0 \quad (f_𝜃(x) < 0.5) \end{matrix}\right.\)
回頭看 S 函數,當 \(f_𝜃(x) \geq 0.5\),也就是 \(𝜃^T x >0\) ,就判定為橫向。可將判斷式改為
\(y = \left\{\begin{matrix} 1 \quad (𝜃^T x \geq 0) \\ 0 \quad (𝜃^T x < 0) \end{matrix}\right.\)
任意選擇一個 𝜃 為例子,\(x_1\) 是橫長, \(x_2\) 是高
\(𝜃= \left[ \begin{matrix} 𝜃_0 \\ 𝜃_1 \\𝜃_2 \end{matrix} \right] = \left[ \begin{matrix} -100 \\ 2 \\ 1 \end{matrix} \right] , x= \left[ \begin{matrix} 1 \\ x_1 \\x_2 \end{matrix} \right] \)
\(𝜃^T x = -100 \cdot 1 +2x_1 +x_2 \geq 0 \)
\( x_2 \geq -2x_1 +100 \) 就表示分類為橫向
以圖形表示

以 \(𝜃^Tx =0\) 這條直線為邊界線,就能區分橫向或縱向,這條線就是決策邊界。但實際上,這個任意選擇的 𝜃 並不能正確的進行分類,因此為了求得正確的 𝜃 ,就要定義目標函數,進行微分,以求得正確的參數 𝜃 ,這個方法就稱為邏輯迴歸。
似然函數
現在要找到 𝜃 的更新式
一開始將 x 為橫向的機率 \(P( y = 1 | x) \) 定義為 \(f_𝜃(x)\) ,根據這個定義,學習資料 \(y\) 跟 \(f_𝜃(x)\) 的關係,最佳的狀況是 \(y=1, f_𝜃(x)=1\) , \(y=0, f_𝜃(x)=0\) ,但還要改寫為
- \( y=1 \) 時,要讓機率 \(P( y = 1 | x) \) 是最大,判定為橫向
- \( y=0 \) 時,要讓機率 \(P( y = 0| x) \) 是最大,判定為縱向
| 矩形大小 | 形狀 | \(y\) | 機率 |
|---|---|---|---|
| 80 x 150 | 縱向 | 0 | 要讓機率 $P( y = 0 |
| 60 x 110 | 縱向 | 0 | 要讓機率 $P( y = 0 |
| 160 x 50 | 橫向 | 1 | 要讓機率 $P( y = 1 |
| 125 x 30 | 橫向 | 1 | 要讓機率 $P( y = 1 |
因為所有學習資料互相獨立沒有關聯,整體的機率就是全部的機率相乘
\(L(𝜃) = P( y^{(1)} = 0|x^{(1)} ) P( y^{(2)} = 0|x^{(2)} ) P( y^{(3)} = 1|x^{(3)} ) P( y^{(4)} = 1|x^{(4)} ) \)
這個式子可改寫為
\(L(𝜃) = \prod _{i=1}^{n} P( y^{(i)} = 1|x^{(i)} )^{y^{(i)}} P( y^{(i)} = 0|x^{(i)} )^{1-y^{(i)}}\)
如果假設 \(y^{(i)} = 1\)
\(P( y^{(i)} = 1|x^{(i)} )^1 P( y^{(i)} = 0|x^{(i)} )^0 = P( y^{(i)} = 1|x^{(i)} )\)
如果假設 \(y^{(i)} =0 \)
\(P( y^{(i)} = 1|x^{(i)} )^0 P( y^{(i)} = 0|x^{(i)} )^1 = P( y^{(i)} = 0|x^{(i)} )\)
目標函數 \(L(𝜃)\) 就稱為似然函數 Likelihood,就是要找到讓 \(L(𝜃)\) 最大的參數 𝜃
對數似然函數
因為機率都小於 1,機率的乘積會不斷變小,在程式設計會產生精確度的問題。所以加上 log
\(\log L(𝜃) = \log \prod _{i=1}^{n} P( y^{(i)} = 1|x^{(i)} )^{y^{(i)}} P( y^{(i)} = 0|x^{(i)} )^{1-y^{(i)}}\)
因為 log 是單調遞增函數,因此不會影響到結果。換句話說,要讓 \(L(𝜃)\) 最大化,跟要讓 \(logL(𝜃)\) 最大化是一樣的。
\(\begin{equation}
\begin{split}
\log L(𝜃) &= \log \prod _{i=1}^{n} P( y^{(i)} = 1|x^{(i)} )^{y^{(i)}} P( y^{(i)} = 0|x^{(i)} )^{1-y^{(i)}}\\
&=\sum_{i=1}^{n}( \log P( y^{(i)} = 1|x^{(i)} )^{y^{(i)}} + log P( y^{(i)} = 0|x^{(i)} )^{1-y^{(i)}} ) \\
&=\sum_{i=1}^{n}( {y^{(i)}} \log P( y^{(i)} = 1|x^{(i)} ) + ({1-y^{(i)}}) \log P( y^{(i)} = 0|x^{(i)} ) ) \\
&=\sum_{i=1}^{n}( {y^{(i)}} \log P( y^{(i)} = 1|x^{(i)} ) + ({1-y^{(i)}}) \log (1-P( y^{(i)} = 1|x^{(i)} )) ) \\
&=\sum_{i=1}^{n}( {y^{(i)}} \log f_𝜃( x^{(i)} ) + ({1-y^{(i)}}) \log (1- f_𝜃(x^{(i)} )) ) \\
\end{split}
\end{equation}\)
- \(\log(ab) = \log a + \log b\)
- \(\log a^b = b \log a\)
- 因為只考慮 \(y=1\) 或 \(y=0\),所以 \(P( y^{(i)} = 0|x^{(i)} ) = 1 - P( y^{(i)} = 1|x^{(i)} )\)
似然函數的微分
邏輯迴歸,就是將這個對數似然函數當作目標函數使用
\( \log L(𝜃) =\sum_{i=1}^{n}( {y^{(i)}} \log f_𝜃( x^{(i)} ) + ({1-y^{(i)}}) \log (1- f_𝜃(x^{(i)} )) ) \)
要將這個函數,個別針對參數 \(𝜃_j\) 進行偏微分
同樣利用合成函數的微分方法
\( u = \log L(𝜃)\)
\(v = f_𝜃 (x) = \frac{1}{1 + exp(-𝜃^Tx)}\)
然後
\(\frac{𝜕E}{𝜕𝜃_j} = \frac{𝜕u}{𝜕v} \frac{𝜕v}{𝜕𝜃_j}\)
先計算第一項
因為 \(\log (v)\) 的微分是 \(\frac{1}{v}\)
而 \( \log (1-v)\) 的微分為
\( s =1-v \)
\( t = \log (s) \)
\( \frac{dt}{dv} = \frac{dt}{ds} \cdot \frac{ds}{dv} = \frac{1}{s} \cdot -1 = - \frac{1}{1-v} \)
所以
\( \frac{𝜕u}{𝜕v} = \frac{𝜕}{𝜕v} \sum_{i=1}^{n}( {y^{(i)}} \log (v) + ({1-y^{(i)}}) \log (1- v ) ) = \sum_{i=1}^{n} ( \frac{y^{(i)}}{v} - \frac{1- y^{(ii)} }{1-v} )\)
然後將 \(v\) 以 \(𝜃_j\) 微分
\(\frac{𝜕v}{𝜕𝜃_j} = \frac{𝜕}{𝜕𝜃_j} \frac{1}{ 1+ exp(-𝜃^Tx)} \)
因為 \(f_𝜃 (x)\) 是 S 型函數,且已知 S 型函數的微分為
\( \frac{d𝜎(x)}{dx} = 𝜎(x) (1-𝜎(x)) \)
利用合成函數的微分方法
\( z = 𝜃^T x\)
\(v = f_𝜃 (x) = \frac{1}{1 + exp(-z)}\)
\(\frac{𝜕v}{𝜕𝜃_j} = \frac{𝜕v}{𝜕z} \frac{𝜕z}{𝜕𝜃_j} \)
前面的部分
\( \frac{𝜕v}{𝜕z} = v(1-v) \)
後面的部分
\( \frac{𝜕z}{𝜕𝜃_j} = \frac{𝜕}{𝜕𝜃_j} 𝜃^Tx = \frac{𝜕}{𝜕𝜃_j} (𝜃_0x_0 +𝜃_1x_1 +\cdots + 𝜃_nx_n ) = x_j \)
所以
\(\frac{𝜕v}{𝜕𝜃_j} = \frac{𝜕v}{𝜕z} \frac{𝜕z}{𝜕𝜃_j} = v(1-v) x_j \)
\(\begin{equation}
\begin{split}
\frac{𝜕u}{𝜕𝜃_j} &= \frac{𝜕u}{𝜕v} \frac{𝜕v}{𝜕𝜃_j} \\
& = \sum_{i=1}^{n}( \frac{y^{(i)}}{v} - \frac {1 - y^{(i)}}{1-v} ) \cdot v(1-v) \cdot x_j^{(i)} \\
& = \sum_{i=1}^{n}( y^{(i)}(1-v) - (1-y^{(i)})v )x_j^{(i)} \\
& = \sum_{i=1}^{n}( y^{(i)} -v )x_j^{(i)} \\
& = \sum_{i=1}^{n}( y^{(i)} - f_𝜃(x^{(i)}) )x_j^{(i)} \\
\end{split}
\end{equation}\)
先前最小化,是要往微分後的結果的正負符號相反方向移動。但現在要最大化,所以要往微分後的結果的正負符號相同方向移動。
\( 𝜃_j := 𝜃_j + 𝜂 \sum_{i=1}^{n}( y^{(i)} - f_𝜃(x^{(i)}) )x_j^{(i)} \)
也能配合多元迴歸,改寫成這樣
\(𝜃_j := 𝜃_j - 𝜂 \sum_{i=1}^{n}( f_𝜃(x^{(i)}) - y^{(i)} )x_j^{(i)}\)
線性不可分離
線性不可分離的問題不能直線,但可嘗試用曲線。
例如,將 \(x_1^2\) 加入學習資料
\(𝜃= \left[ \begin{matrix} 𝜃_0 \\ 𝜃_1 \\𝜃_2 \\𝜃_3 \end{matrix} \right] , x= \left[ \begin{matrix} 1 \\ x_1 \\x_2 \\x_1^2\end{matrix} \right] \)
然後
\( 𝜃^Tx = 𝜃_0+𝜃_1x_1+𝜃_2x_2+𝜃_3x_1^2 \)
假設
\(𝜃= \left[ \begin{matrix} 𝜃_0 \\ 𝜃_1 \\𝜃_2 \\𝜃_3 \end{matrix} \right] = \left[ \begin{matrix} 0 \\ 0 \\1 \\-1 \end{matrix} \right] \)
因為 \(𝜃^Tx \geq 0\)
\( 𝜃^Tx = 𝜃_0+𝜃_1x_1+𝜃_2x_2+𝜃_3x_1^2 = x_2 - x_1^2 \geq 0 \)
得到方程式 \( x_2 \geq x_1^2 \)
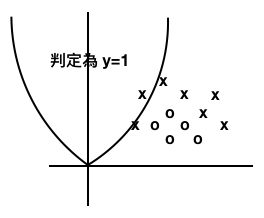
現在的決策邊界變成曲線,因為參數 𝜃 是任意選擇的,所以資料沒有被正確地分類。
可以增加次方數,得到複雜的形狀的決策邊界。
另外還有 SVM (支援向量機) 的分類演算法,多元分類處理方法。


