keras 是 python 語言的機器學習套件,後端能使用 Google TensorFlow, Microsoft CNTK 或 Theano 運作。其中 Theano 在 2017/9/28 就宣佈在 1.0 後就不再更新。一般在初學機器學習時,都是用手寫阿拉伯數字 MNIST 資料集進行測試,kaggle Digit Recognizer 有針對 MNIST data 的機器學習模型的評比,比較厲害的,都可以達到 100% 的預測結果。
CentOS 7 Keras, TensorFlow docker 測試環境
docker run -it --name c1 centos:latest /bin/bash安裝一些基本工具,以及 openssh-server
#yum provides ifconfig
yum install -y net-tools telnet iptables sudo initscripts
yum install -y passwd openssl openssh-server
yum install -y wget vim測試 sshd
/usr/sbin/sshd -D
Could not load host key: /etc/ssh/ssh_host_rsa_key
Could not load host key: /etc/ssh/ssh_host_ecdsa_key
Could not load host key: /etc/ssh/ssh_host_ed25519_key缺少了一些 key
ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
#直接 enter 即可
ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
#直接 enter 即可
ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key -N ""
ssh-keygen -t ed25519 -f /etc/ssh/ssh_host_ed25519_key -N ""修改 UsePAM 設定
vi /etc/ssh/sshd_config
# UsePAM yes 改成 UsePAM no
UsePAM no再測試看看 sshd
/usr/sbin/sshd -D&修改 root 密碼
passwd root離開 docker
exit以 docker ps -l 找到剛剛那個 container 的 id
$ docker ps -l
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
107fb9c3fc0d centos:latest "/bin/bash" 7 minutes ago Exited (0) 2 seconds ago c1將 container 存成另一個新的 image
docker commit 107fb9c3fc0d centosssh以新的 image 啟動另一個 docker instance
(port 10022 是 ssh,15900 是 vnc)
(--privileged=true 是避免 systemd 發生的 Failed to get D-Bus connection: Operation not permitted 問題)
docker run -d -p 10022:22 -p 15900:5900 -e "container=docker" --ulimit memlock=-1 --privileged=true -v /sys/fs/cgroup:/sys/fs/cgroup --name test centosssh /usr/sbin/init
docker exec -it test /bin/bash現在可以直接 ssh 登入新的 docker machine
ssh root@localhost -p 10022修改 timezone, locale
timedatectl set-timezone Asia/Taipei把 yum.conf 的 overrideinstalllangs 註解掉
vi /etc/yum.conf
#override_install_langs=en_US.utf8yum -y -q reinstall glibc-commonlocalectl list-locales|grep zh
# 會列出所有可設定的 locale
zh_CN
zh_CN.gb18030
zh_CN.gb2312
zh_CN.gbk
zh_CN.utf8
zh_HK
zh_HK.big5hkscs
zh_HK.utf8
zh_SG
zh_SG.gb2312
zh_SG.gbk
zh_SG.utf8
zh_TW
zh_TW.big5
zh_TW.euctw
zh_TW.utf8
# 將 locale 設定為 zh_TW.utf8
localectl set-locale LANG=zh_TW.utf8安裝視窗環境及VNC
ref: https://www.jianshu.com/p/38a60776b28a
yum groupinstall -y "GNOME Desktop"
# 預設啟動圖形介面
unlink /etc/systemd/system/default.target
ln -sf /lib/systemd/system/graphical.target /etc/systemd/system/default.target
# 安裝 vnc server
yum -y install tigervnc-server tigervnc-server-module
# vnc 預設的port tcp 5900,則組態檔複製時在檔名中加入0,如vncserver@:0.service,如果要使用其他的port,就把0改為其他號碼
cp /lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@:0.service
vi /etc/systemd/system/vncserver@:0.service
# 修改中間的部分
ExecStartPre=/bin/sh -c '/usr/bin/vncserver -kill %i > /dev/null 2>&1 || :'
ExecStart=/usr/sbin/runuser -l root -c "/usr/bin/vncserver %i -geometry 1280x1024"
PIDFile=/root/.vnc/%H%i.pid
ExecStop=/bin/sh -c '/usr/bin/vncserver -kill %i > /dev/null 2>&1 || :'
# 執行 vncpasswd 填寫 vnc 密碼
su root
vncpasswd
# 退出 container
exit
# restart docker container
docker restart test
# 進入 docker container
docker exec -it test /bin/bash
# 啟動 service
systemctl daemon-reload
systemctl start vncserver@:0.service
systemctl enable vncserver@:0.service
# 開啟防火牆允許VNC的連線,以及重新load防火牆,這邊多開放了port 5909。
firewall-cmd --permanent --add-service="vnc-server" --zone="public"
#firewall-cmd --add-port=5909/tcp --permanent
firewall-cmd --reload
vncserver -list
# 以 vnc client 連線,連接 localhost:15900如果用 vnc 連線到 docker 機器,後面測試時,matplotlib 可直接把圖形畫在視窗上,就不用存檔。
安裝 TensorFlow, python 3.6 開發環境
yum -y install centos-release-scl
yum -y install rh-python36
python --version
# Python 2.7.5
# 目前還是 python 2.7,必須 enable 3.6
scl enable rh-python36 bash
python --version
# Python 3.6.3但每次登入都還是 2.7
vi /etc/profile.d/rh-python36.sh
#!/bin/bash
source scl_source enable rh-python36接下來每次登入都是 3.6
安裝 TensorFlow
pip3 install --upgrade tensorflow
# 更新 pip
pip3 install --upgrade pip簡單測試,是否有安裝成功
# python
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
print(sess.run(hello))
# 會列印出這樣的結果
# b'Hello, TensorFlow!'
#---------
python -c "import tensorflow as tf; tf.enable_eager_execution(); print(tf.reduce_sum(tf.random_normal([1000, 1000])))"
# 會列印出這樣的結果
# tf.Tensor(12.61731, shape=(), dtype=float32)
再安裝 keras, matplotlib (需要 tk library)
pip3 install keras
yum -y install rh-python36-python-tkinter
pip3 install matplotlib阿拉伯數字辨識
MNIST 是一個包含 60,000 training images 及 10,000 testing images 的手寫阿拉伯數字的測試資料集。資料集的每個圖片都是解析度為 28*28 (784 個 pixel) 的灰階影像, 每個像素為 0~255 之數值。
One-Hot Encoding 就是一位有效編碼,當有 N 種狀態,就使用 N 位狀態儲存器的編碼,每一個狀態都有固定的位置。
例如阿拉伯數字就是 0 ~ 9,就使用這樣的編碼方式
[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.] 代表 0
...
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.] 代表 5
...
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.] 代表 9程式處理的步驟如下:
- 取得訓練資料:目前是直接使用既有的 MNIST 資料集,利用這些既有的資料,進行機器學習。
- 機器訓練,取得模型:進行機器訓練,取得訓練後結果的模型,未來就可以利用這個模型,判斷新進未知的資料
- 評估:利用 MNIST 資料集的測試資料,評估模型判斷後的結果跟正確結果的差異,取得這個模型的準確率。
- 預測:未來可利用這個模型,判斷並預測新進資料的結果。當然這會因為上一個步驟的準確度,有時候會失準,不一定會完全正確。
以下這個例子是使用 Sequential 線性的模型,input layer 是 MNIST 60000 筆訓練資料,中間是一層有 256 個變數的 hidden layer,最後是 10 個變數 (0~9) 的 output layer。機器學習就是在產生 input layer 到 hidden layer,以及 hidden layer 到 output layer 中間的 weight 權重。
input layer --- W(i,j) ---> hidden layer (256 個變數) --- W(j, k) ---> output layer (0~9) 測試程式 test.py
import numpy as np
from keras.models import Sequential
from keras.datasets import mnist
from keras.layers import Dense, Dropout, Activation, Flatten
# 用來後續將 label 標籤轉為 one-hot-encoding
from keras.utils import np_utils
from matplotlib import pyplot as plt
# 載入 MNIST 資料庫的訓練資料,並分為 training 60000 筆 及 testing 10000 筆 data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 將 training 的 label 進行 one-hot encoding,例如數字 7 經過 One-hot encoding 轉換後是 array([0., 0., 0., 0., 0., 0., 0., 1., 0., 0.], dtype=float32),即第7個值為 1
y_train_onehot = np_utils.to_categorical(y_train)
y_test_onehot = np_utils.to_categorical(y_test)
# 將 training 的 input 資料轉為 28*28 的 2維陣列
# training 與 testing 資料數量分別是 60000 與 10000 筆
# X_train_2D 是 [60000, 28*28] 的 2維陣列
x_train_2D = x_train.reshape(60000, 28*28).astype('float32')
x_test_2D = x_test.reshape(10000, 28*28).astype('float32')
x_train_norm = x_train_2D/255
x_test_norm = x_test_2D/255
# 建立簡單的線性執行的模型
model = Sequential()
# Add Input layer, 隱藏層(hidden layer) 有 256個輸出變數
model.add(Dense(units=256, input_dim=784, kernel_initializer='normal', activation='relu'))
# Add output layer
model.add(Dense(units=10, kernel_initializer='normal', activation='softmax'))
# 編譯: 選擇損失函數、優化方法及成效衡量方式
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 進行 model 訓練, 訓練過程會存在 train_history 變數中
# 將 60000 張 training set 的圖片,用 80% (48000張) 訓練模型,用 20% (12000張) 驗證結果
# epochs 10 次,就是訓練做了 10 次
# batch_size 是 number of samples per gradient update,每一次進行 gradient descent 使用幾個 samples
# verbose 是 train_history 的 log 顯示模式,2 表示每一輪訓練,列印一行 log
train_history = model.fit(x=x_train_norm, y=y_train_onehot, validation_split=0.2, epochs=10, batch_size=800, verbose=2)
# 用 10000 筆測試資料,評估訓練後 model 的成果(分數)
scores = model.evaluate(x_test_norm, y_test_onehot)
print()
print("Accuracy of testing data = {:2.1f}%".format(scores[1]*100.0))
# 預測(prediction)
X = x_test_norm[0:10,:]
predictions = model.predict_classes(X)
# get prediction result
print()
print(predictions)
# 模型訓練結果 結構存檔
from keras.models import model_from_json
json_string = model.to_json()
with open("model.config", "w") as text_file:
text_file.write(json_string)
# 模型訓練結果 權重存檔
model.save_weights("model.weight")
# 顯示 第一筆訓練資料的圖形,確認是否正確
#plt.imshow(x_train[0])
#plt.show()
#plt.imsave('1.png', x_train[0])
plt.clf()
plt.plot(train_history.history['loss'])
plt.plot(train_history.history['val_loss'])
plt.title('Train History')
plt.ylabel('loss')
plt.xlabel('Epoch')
plt.legend(['loss', 'val_loss'], loc='upper left')
#plt.show()
plt.savefig('loss.png')
執行結果
# python test.py
Using TensorFlow backend.
Train on 48000 samples, validate on 12000 samples
Epoch 1/10
- 2s - loss: 0.7582 - acc: 0.8134 - val_loss: 0.3195 - val_acc: 0.9117
Epoch 2/10
- 1s - loss: 0.2974 - acc: 0.9160 - val_loss: 0.2473 - val_acc: 0.9307
Epoch 3/10
- 2s - loss: 0.2346 - acc: 0.9350 - val_loss: 0.2060 - val_acc: 0.9425
Epoch 4/10
- 2s - loss: 0.1930 - acc: 0.9465 - val_loss: 0.1741 - val_acc: 0.9522
Epoch 5/10
- 2s - loss: 0.1631 - acc: 0.9539 - val_loss: 0.1529 - val_acc: 0.9581
Epoch 6/10
- 2s - loss: 0.1410 - acc: 0.9604 - val_loss: 0.1397 - val_acc: 0.9612
Epoch 7/10
- 1s - loss: 0.1225 - acc: 0.9662 - val_loss: 0.1301 - val_acc: 0.9639
Epoch 8/10
- 1s - loss: 0.1075 - acc: 0.9695 - val_loss: 0.1171 - val_acc: 0.9668
Epoch 9/10
- 1s - loss: 0.0948 - acc: 0.9744 - val_loss: 0.1123 - val_acc: 0.9681
Epoch 10/10
- 1s - loss: 0.0855 - acc: 0.9771 - val_loss: 0.1047 - val_acc: 0.9700
10000/10000 [==============================] - 1s 57us/step
Accuracy of testing data = 97.1%
[7 2 1 0 4 1 4 9 6 9]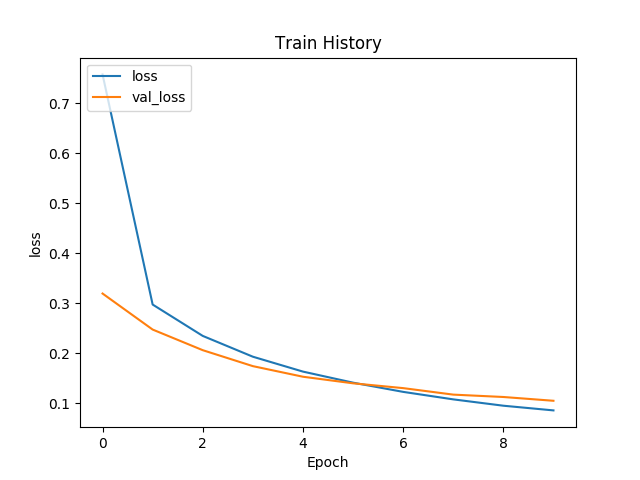
Model Persistence
要儲存訓練好的模型,有兩種方式
結構及權重分開儲存
儲存模型結構,可儲存為 JSON 或 YAML
from keras.models import model_from_json json_string = model.to_json() with open("model.config", "w") as text_file: text_file.write(json_string)
儲存權重
model.save_weights("model.weight")
讀取結構及權重
import numpy as np from keras.models import Sequential from keras.models import model_from_json with open("model.config", "r") as text_file: json_string = text_file.read() model = Sequential() model = model_from_json(json_string) model.load_weights("model.weight", by_name=False)合併儲存結構及權重
合併儲存時,檔案格式為 HDF5
from keras.models import load_model model.save('model.h5') # creates a HDF5 file 'model.h5'
讀取模型
from keras.models import load_model # 載入模型 model = load_model('model.h5')
References
【深度學習框架 Theano 慘遭淘汰】微軟數據分析師:為何曾經熱門的 Theano 18 個月就陣亡?
撰寫第一支 Neural Network 程式 -- 阿拉伯數字辨識
mnist-cnn/mnist-CNN-datagen.ipynb
沒有留言:
張貼留言